Para empezar con este blog comenzaré hablando sobre ese tipo de utilidades que tan poco parecen ser utilizadas: estoy hablando de los "profilers" o analizadores.
¿Qué es un profiler?
Un profiler es una herramienta que nos ayuda a encontrar y a identificar cuellos de botella en nuestras aplicaciones JAVA: situaciones en las que nuestras aplicaciones se vuelven incomprensiblemente lentas o consumen más memoria de lo deseable o recomendable. Estas herramientas acostumbran a ofrecer una visión detallada sobre el consumo de cpu y de memoria y ayudan a identificar qué ocupa esa memoria o en qué invierte el tiempo de cpu el programa.
Lo cierto es que cuando uno abre por primera vez una de estas herramientas y ve todo lo que hay dentro se marea un poco, así que compartiré con vosotros alguna de mis últimas experiencias para que os hagáis una ligera idea de como le podéis sacar partido a esto.
Existen muchos y muy buenos profilers para Java, algunos de los que he oído nombrar y/o he tenido oportunidad de utilizar son:
Hay muchos otros y muchos de ellos disponen de características muy interesantes que ayudan a realizar análisis muy detallados de diferentes aspectos de un programa, aunque en esta entrada hablaré de Visual VM, el cual además de ser gratuito es muy fácil de usar y cubre la mayor parte de las necesidades que pueda tener un programador / analista a la hora de encontrar problemas y cuellos de botella.
¿A quién le puede interesar un profiler?
Un profiler es una herramienta interesante para cualquier persona que desempeñe alguno de los siguientes roles:
- Desarrollador de aplicaciones JAVA
- Administrador encargado de supervisar servidores de aplicaciones Java.
- Analista encargado de realizar pruebas de rendimiento a aplicaciones Java.
- Cualquier técnico o usuario que quiera proporcionar un informe de error detallado sobre un bug de una aplicación Java.
- Cualquier curioso que le guste mirar las entrañas de una aplicación Java ... :)
¿Qué me puede ofrecer Visual VM?
Visual VM funciona conéctandose a una máquina virtual Java que ejecute la aplicación que queráis analizar, una vez conectado tiene acceso a cualquier dato o detalle de dicha máquina virtual y os permite hacer las siguientes cosas:
- Podeis analizar aplicaciones que se ejecutan en una máquina virtual Java local (la de tu ordenador) o en una máquina virtual de un equipo remoto (por ejemplo el servidor de desarrollo que compartes con tus compañeros de fatigas).
- Os permite consultar todo tipo de información sobre la máquina virtual a la que se haya conectado:
- Argumentos de inicialización de la máquina virtual.
- Propiedades de sistema de la máquina virtual.
- Gráficas de consumo de cpu, memoria heap y PermGen, número de clases cargadas, número de hilos / threads.
- Lista de hilos / threads y actividad de los mismos.
- Realizar volcados de threads, pila.
- Cargar, analizar y explorar volcados de pila y de nucleo (core dump).
- Analiza en tiempo real el consumo de CPU (desglose de ocupación de CPU) y de memoria (lista de clases cargadas, número de instancias de cada clase).
- Crear "capturas" o "fotos" (snapshots) del estado de la memoria o de la CPU en un instante concreto. Esta característica es muy interesante para poder hacer comparativas o análisis "offline".
- En los volcados de pila podemos navegar dentro de sus contenidos viendo los objetos y sus contenidos.
- Permite realizar consultas y filtros ad-hoc sobre los contenidos de los volcados como si realizáramos una consulta sobre una base de datos, usando un lenguaje de consultas llamado OQL (Object Query Language).
Hasta aquí la promoción gratuita de la aplicación, imagino que querréis ver de qué manera se utiliza la aplicación, a continuación os resumo una de mis últimas experiencias con esta herramienta.
Bien, pues erase una vez :) una aplicación web JAVA que se ejecutaba en un servidor de aplicaciones jboss y consumía mucha memoria, ¿os suena de algo el cuento?, tanto era así que cada vez que era probada el servidor se quedaba sin memoria heap. El servidor tenía mucha memoria asignada para su heap y no estaba siendo usado por nadie más así que no cabía mucho la excusa acerca de que la memoria se la estuviera comiendo otra aplicación.
Alguien me pidió si era posible averiguar qué hacía que la aplicación usara tanta memoria así que armado con mi herramienta Visual VM, me puse a investigar un poco que se estaba cociendo allí. Tomé la aplicación y la desplegué en mi servidor JBoss local, arranqué el servidor y desde Visual VM me conecté.
 |
| Lista de aplicaciones activas en el equipo local |
Al acceder al proceso "Jboss" local empecé a obtener más información, de entrada las propiedades generales de la máquina virtual a la que me acababa de conectar:
 |
| Resumen propiedades Visual VM
El problema que estoy investigando tenía que ver con el consumo de memoria en un escenario concreto, que se daba cuando el usuario de la aplicación realizaba una acción concreta, así que repetí la acción y me dispuse a investigar más a fondo, ... ¿por dónde empezar?, bueno hay varias opciones, primero me perdí un rato mirando entre las pestañas de detalle de la máquina virtual que estaba inspeccionado, concretamente me fui a la pestaña "monitor" dónde pude constatar gracias a las gráficas que vi allí que efectivamente el tamaño de la memoria de pila había crecido después que realizara la acción.
|
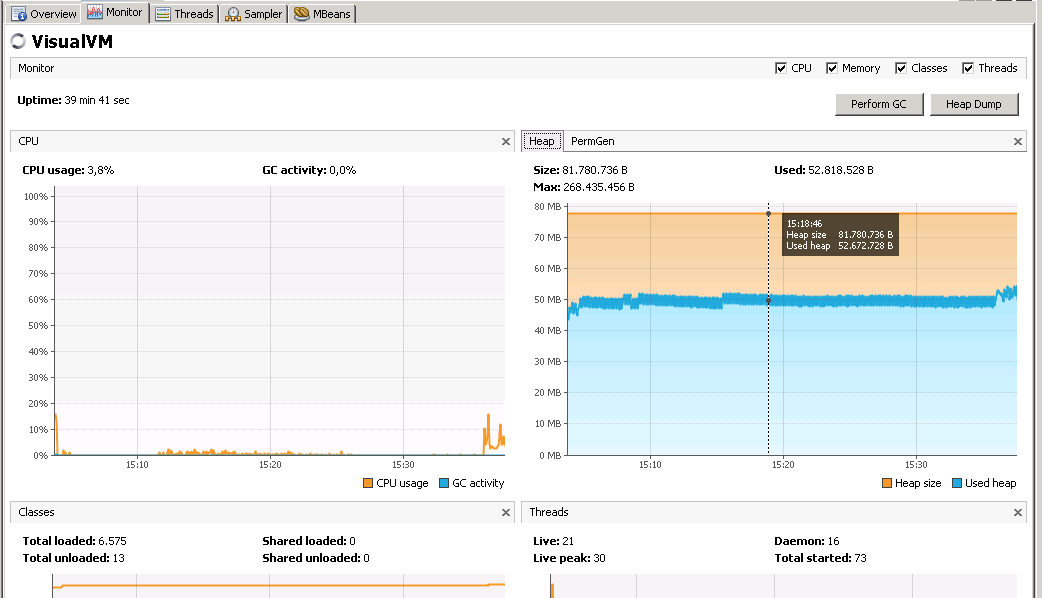 |
| Ejemplo de la pestaña "monitor" de la máquina virtual
Bueno, pero esto no me resolvía el problema, solo me daba pistas de que efectivamente andaba en la dirección correcta, ¿cómo llegaría a identificar el motivo del crecimiento de la memoria?, después de estar buscando un modo entre la documentación de Visual VM fui a dar con el principio de la solución, si quería esa información necesitaba muestras de datos de la máquina virtual. Wait a minute? ¿muestras de datos? pues si, es un poco parecido a cuando quieres llevar a cabo un estudio estadístico, hasta que no tienes una base muestral significativa no puedes realizar el estudio, y además no valía cualquier base muestral, tenía que ser una base muestral "estática" dado que para la acción que quería llevar a cabo necesitaba una "instantánea" del estado de la máquina virtual justo en aquel momento después de realizar la prueba en la que el consumo de memoria se había disparado. Por suerte esto Visual VM te permite realizarlo a las mil maravillas, primero de todo si quieres muestras de datos en vivo y cambiantes en tiempo real debes ir a la pestaña Sampler (muestreador en inglés). Allí en función del tipo de muestras que quieras obtener debes seleccionar un botón u otro: CPU o Memory, en mi caso la elección era fácil, enchufé el Memory y empezó el baile de datos delante mío ...
|
 |
| Muestras en vivo de estadísticas de clases
Delante de mis ojos estaban bailando las cifras , pero a ver, ¿qué era todo aquello? después de mirarlo unos segundos comencé a entender, estaba viendo las estadísticas de las clases que había cargadas en memoria, junto con el número de bytes que ocupaban dichas clases y el número de instancias que tenían. Lo de decir que era un baile "en vivo" no es para nada exagerado porque iban cambiando de posición en la tabla constantemente, aunque eso si las clases de las primeras posiciones de la tabla no se movían mucho.
Al ver la casilla de texto de la parte inferior , donde dice "Class Name Filter" me sentí tentado de escribir el nombre del paquete que pertenecía a la aplicación que estaba investigando (y de la que tenía el código fuente), al hacerlo voilá! automaticamente aparecieron únicamente las clases de mi aplicación, pero me llevé una decepción al ver que en porcentaje ninguna de ellas representaba ningún volumen significativo de datos (ni siquiera un 1%). Algo no encajaba, y era normal que fuera así dado que poco después descubrí que los volúmenes de datos expresados para cada clase representaban el tamaño que las instancias de dichas clases ocupaban en la memoria virtual, pero para cada clase por separado, esto es, si una clase tenía un atributo de otro tipo (por ejemplo char[]) el tamaño ocupado por los valores de dichos atributos no eran sumados al de la clase contenedora. Además tampoco era posible ver las instancias de dichas clases. Al final resulta normal que las clases con mayor volumen de datos fueran de tipos de datos primitivos o arrays de estos dado que en última instancia todo está construido sobre estos.
Con tanto baile de números arriba y abajo era difícil que pudiera tener una imagen estable de lo que pasaba, así que aquí vino la segunda parte: había que tomar una instantánea del estado de la aplicación en pleno estado de colapso de la memoria. Tomar una instántanea de aquella situación no podía ser mas fácil: Haces clic en el botón "Snapshot" encima de la tabla y obtienes una captura de la misma tabla pero congelada. Pero seguía con el mismo problema, ¿como ver qué instancias tenía cada clase y como ver sus contenidos? la respuesta no está lejos: lo que necesitaba era un "Heap Dump" (un volcado de pila de toda la vida... ). De hecho el botón para realizar un Heap Dump no está muy lejos del botón para el snapshot, encima de la tabla a la derecha.
La primera cosa que notas al hacer un "Heap dump" es que Visual VM se queda parado un rato más largo que con un "Snapshot", sobre todo si tu pila está bien cargadita ;) . Al terminar obtienes algo como lo de la siguiente pantalla ...
|
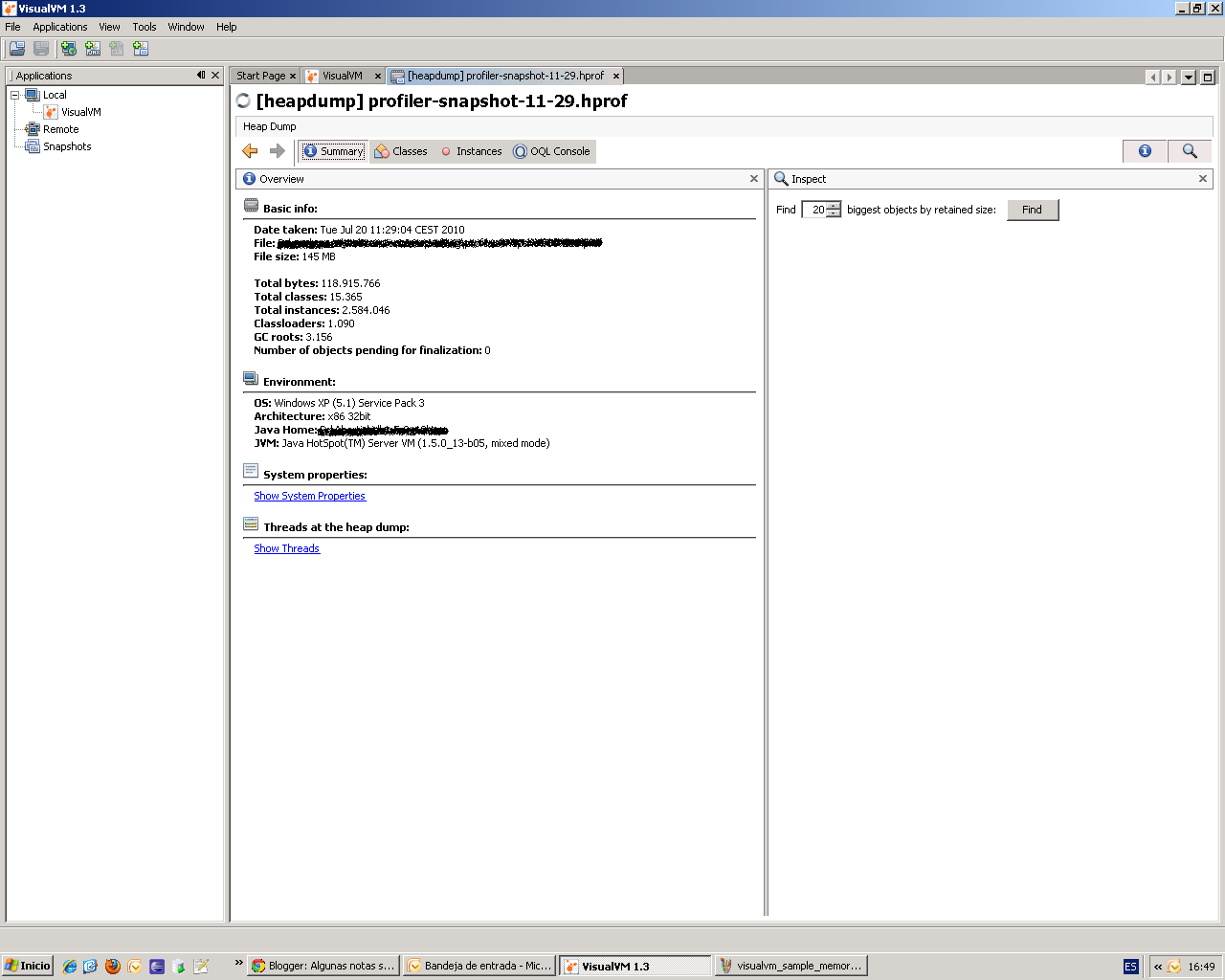 |
| Volcado de pila
Ok, uno empieza a leer de izquierda a derecha y ves la fecha en que se hizo el volcado, el fichero donde se ha guardado el volcado, el tamaño del volcado, # bytes, # clases, propiedades de la máquina virtual, etc ... y de repente te encuentras a la derecha con un panel que pone "Inspect" y debajo pone "Find 20 biggest objects by retained size" y un botón Find, evidentemente si sabes un poco de inglés piensas ... "ahí le has dao", "los cuarenta / 2 principales del consumo de memoria" servidos en bandeja, busqué un poco por el manual para averiguar que quería decir "retained size" y averigué que era el tamaño de un objeto + el de los objetos contenidos, genial! ya estaba en la pista, le di al botón Find. Primero de todo Visual Vm te advierte que va a calcular los "retained sizes" y que eso le va a llevar un rato, así que pensé: "me voy a por un café". Cuando volví, excitado por el café y por el subidón de la expectativa creada encontré la lista de resultados.
|
 |
| Lista de los 20 objetos que consumían más memoria
Después de investigar un rato entre la lista y comencé por descartar aquellos objetos cuya clase no se correspondía con la aplicación que estaba investigando ni con ninguna de sus actividades acabé centrando mi atención en la clase org.apache.catalina.session.StandardManager, después de "googlear" un poco averigué un poco sobre esa clase, por lo que dice en su descripción tiene que ver corresponde con la persistencia de sesiones web de usuario en Tomcat / JBoss. Ese objeto en aquel momento en que realicé el volcado ocupaba la nada despreciable cifra de 5574570 bytes = 5443 kilobytes = 5,31 MB, nada mal (lo de mal era un decir) para una aplicación web JAVA. Por ahí empecé a entender que el problema que estaba buscando estaba relacionado con el tamaño de la sesión.
Además desde el listado se podía clicar en el enlace de la fila correspondiente a la clase y me permitía ver los contenidos de dicho objeto, con lo que pude averiguar más sobre mi problema y navegar dentro del objeto:
|
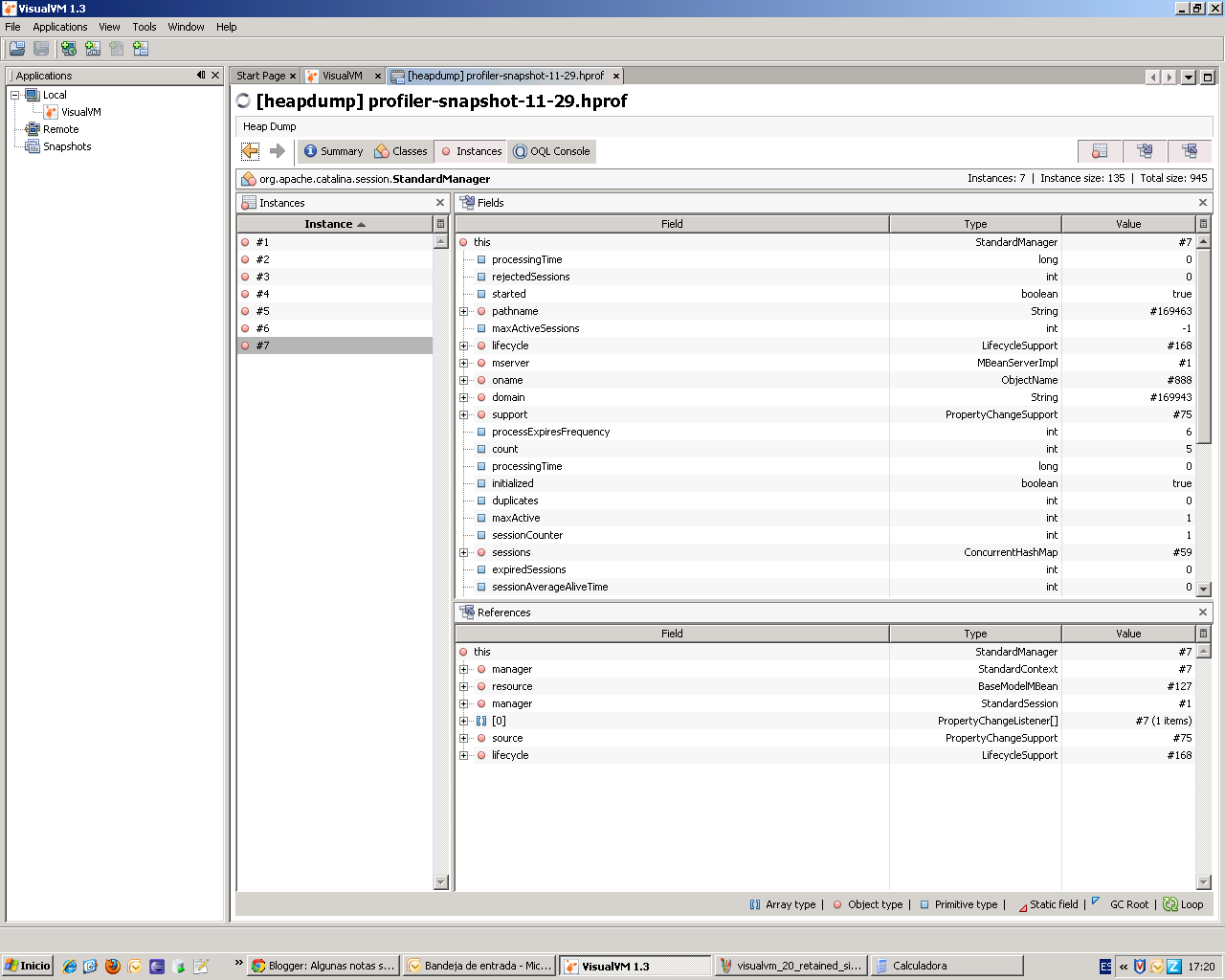 | ||
| Navegando por la pila de memoria, dentro del objeto session de JBoss
Navegar dentro del objeto me permitió visualizar otro detalle interesante: muchos de los objetos que encontré dentro del objeto StandardManager eran de hecho objetos que ya aparecían en el listado inicial (java.util.concurrent.ConcurrentHashMap y derivados ...), después de navegar un poco más dentro de estos objetos acabé dando con un objeto que estaba dentro de una sesión web de usuario cuyo tamaño era casi igual al de toda la sesión.
Otras cosas que podría haber hecho (y que probé)
He descrito una forma de acabar identificando al causante de un problema como un "memory leak" que puede requerir tiempo y paciencia para llevarla a cabo, otras cosas que podría haber hecho y que probablemente hubieran requerido menos tiempo de trabajo hubieran sido las siguientes:
1. Ampliar la lista de objetos con mayor tamaño de la pila Si en el paso inicial después de cargar el volcado de pila hubiera solicitado 40 objetos en vez de veinte hubiera encontrado antes el objeto de mi aplicación que estaba ocupando tanto espacio; resulta fácil reconocerlo por la ruta de paquetes. 2. Usando el lenguaje de consultas OQL Sabiendo que mis problemas tenían que ver con la sesión de usuario podría haberme dedicado a buscar sesiones de usuario (o sea implementaciones de la clase javax.servlet.http.HttpSession), ¿cómo hacer esto? primero hay que saber qué buscas: para averiguar como se llama la clase que implementa esta interfaz en Tomcat usé los javadocs de la API de Tomcat y un poco de Google y acabé dando con el nombre de dicha implementación dentro de Tomcat, en el caso de Tomcat (versiones 5 y 6, ...) / Jboss se llama org.apache.catalina.session.StandardSession . Usando este dato y la consola OQL de Visual Vm puedes hacer cosas realmente espectaculares, como la siguiente:
|


4 comentarios:
Q pasada de articulo, muy bueno maestro, gracias :-)
Muy bueno gustavo, hacia mucho que no leia un post con tanto nivel de detalle. Animo con el blog.?
Gracias!
Lo guardo al delicious. Espero que no tener que usarlo en la vida. Ya tu sabes ;-)
Saludos
Edu
Gran artículo.
Muchas gracias
Publicar un comentario